
本日で10日目です。
1日30分から1時間の時間しか取れませんが、トータルで10時間程度は勉強したことになりますね。
問 「Pyhtonで何かできるようになったか?」
答 「できることが、少しわかった」
先が思いやられる。

今日は、BeautifulSoupでYahoo!ファイナンスの為替情報を抽出します。
参考にしている本

ソースコード
昨日と同じようなコードになります。
#ライブラリを取り込む
from bs4 import BeautifulSoup
import urllib.request as req
#データ取得
url="https://stocks.finance.yahoo.co.jp/stocks/detail/?code=usdjpy"
res = req.urlopen(url)
#BeautifulSoupで解析
soup = BeautifulSoup(res,"html.parser")
#データを抽出
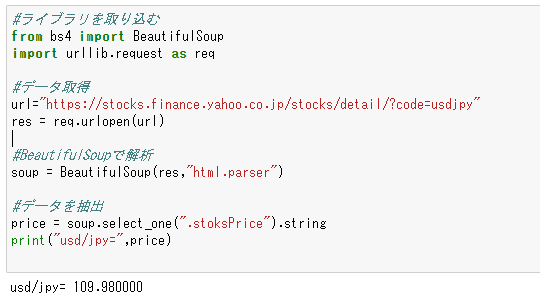
price = soup.select_one(".stoksPrice").string
print("usd/jpy=",price)
soup.select_oneがポイント
「soup.select_one」は、BeautifulSoupで解析したYahooファイナンスのページ=「soup」からselect_oneメソッドでCSSセレクターを1つ取り出すというものです。
これはYahooファイナンスのHTMLが変わっていた場合は、実行結果は変わってくるかと思います。
HTMLに合わせてソースを書き換える必要が出てきます。
「soup.select_one(“.stoksPrice”).string」
「 .stoksPrice 」がレートを示すものです。
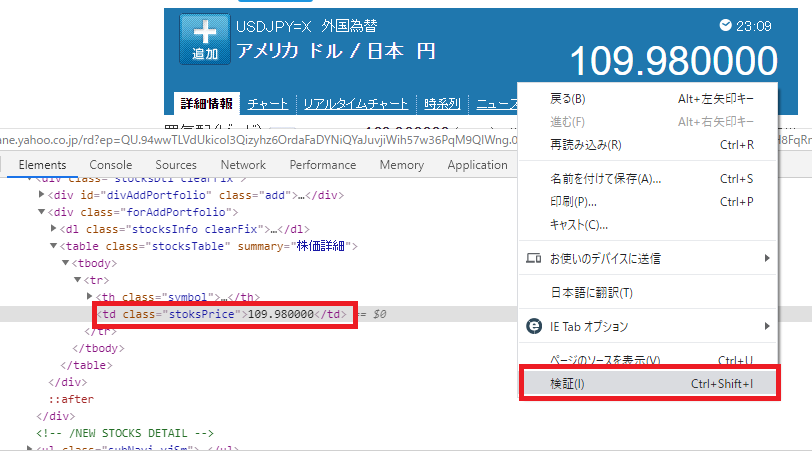
Yahooのページで、レートの109.980000のあたりで右クリックから、検証を選択すると開発画面が出てきます。
そこに<td class=”stoksPrice”>とある部分がレートに位置するところです。
なので、「.stoksPrice」を指定してsoup.select_oneで取得しています。
なるほど、じゃ時間も取りたかったら
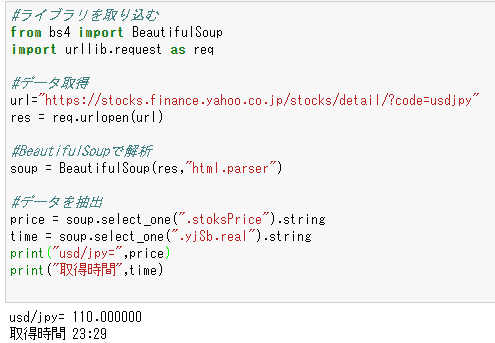
取れましたね。
CSSセレクターを指定することで、狙ったところを取ることが出来ました。
CSSセレクターが同じものが複数あったら?
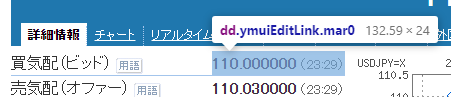
例えばですが、買気配と売気配のレートのところが同じ「ymuiEditLink mar0」というものだったので、試してみました。
ソースでいうとここ。
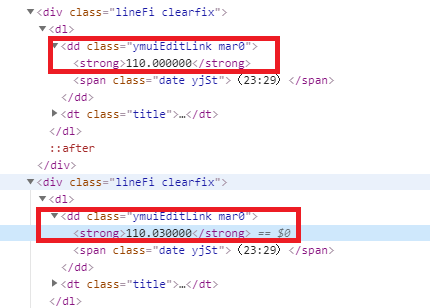
soup.select_one(“.stoksPrice”).stringで指定していたstoksPriceの部分が、「ymuiEditLink mar0」となっていますが、2つあります。

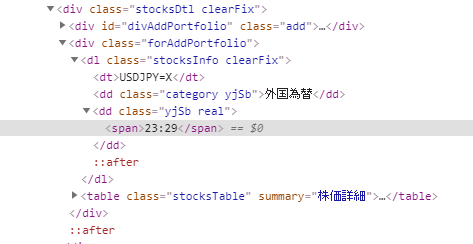
取得時間ってなってますが気にしないでください。
stringを付けるとエラーになります。
付けないと、上記のように出力されます。
「ymuiEditLink mar0」 の中にあるものがすべて抽出された形ですね。
そして、2つあるうちの、最初のほう買気配のほうの値が取れています。
画像をソースでは、時間が経ってしまったので変動してしまっていますが、なんどか試しました。
soup.select_one のoneは最初を取るようです。
ではsoup.select()で試して見ると、2つの値が取れていることが分かります。
stringを付けるとエラーになるので、抽出結果が分かりにくいですが、たぶん何かおまじないの命令を付ければ、きちんと抽出されるのでしょうね。

何度も実行するとサイトのほうに迷惑が掛かってしまうので、数回で止めていますが、とりあえずデータを取るというところは、なんとなくわかってきた気がします。
テストを何回やっても気にならないようなサイトとか公開されているんですかね。
