
昨日に引き続きPython学習2日目です。
無理すると続かなさそうなのでのんびりと行きましょう。
昨日のページ。

昨日の課題から
ライブラリ.モジュール.関数.メソッド
昨日は気にならなかったけど、オブジェクトも必要らしい。
モジュール : 便利なオブジェクトをまとめたファイル
オブジェクト : 便利な関数の塊
メソッド : 便利な関数
と言うことは、だ。
「モジュール.関数.メソッド」は間違いで、「モジュール.オブジェクト.メソッド」が正しいかも知れない。
ライブラリ、どこ行った。
with
with構文は、例えば「ファイルをOpenした後、Closeする」という処理のCloseを省略するような構文でした。
with open(savename,mode=”wb”) as f:
f.write(mem)
print(“保存しました”)
これをwithなしで書くと
f = open(“sample.txt”, “wb”)
print(f.read())
f.close()
こんな感じになるかな。
as f:
asはwithの相方でした。
f:はf=と同じ感じなので、「with 〇〇 as」ってセットで覚えればOKのようです。
この本に沿って進めています

では、続きをやりましょう
WEBからデータを取得する方法
本の中には、練習専用のWEBサイトの記載がありますが、ここでは伏せておきますね。
クライアントの接続情報を表示するAPIです。
#IP確認APIへアクセスして結果を表示する
#モジュールを取り込む
import urllib.request
#データ取得
url="https://***********.com/ip/ini"
res=urllib.request.urlopen(url)
data=res.read()
#バイナリーを文字列に変換
text=data.decode("utf-8")
print(text)
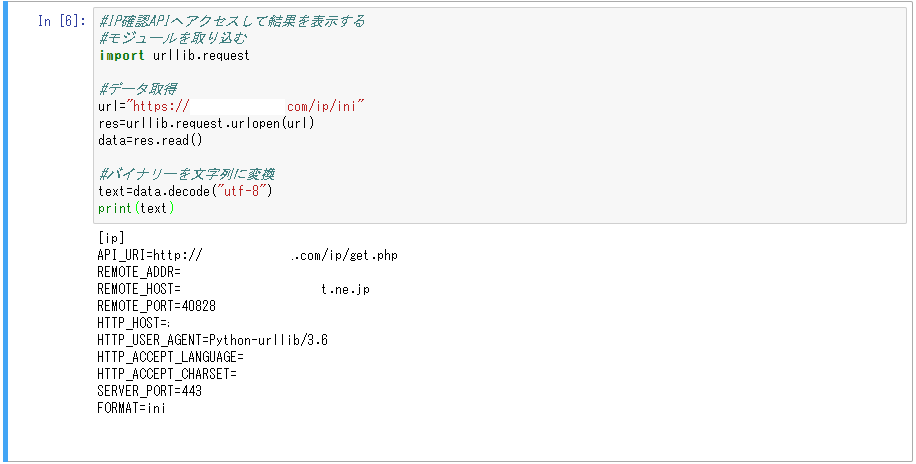
何か返ってきました。
これがなにの役に立つかわからないけど、とりあえず成功です。
コードの前半、データの取得までは昨日と同じですね。
バイナリーに文字列を変換は初めてです。
read()メソッドで読みだすとバイナリーデータになるので、decore()メソッドで文字列に変換しています。utf-8は文字コードだと思いますがこれで文字列になるんですね。
試しに#バイナリーを文字列に変換の部分を行わず、そのまま出してみると。

文字列にするのは必須ですね。
このブログの昨日のpython独学1日目のURLにしてみました。

サイトのhtmlの部分がすべて表示された感じです。
まとめ
urllibを使うと、簡単にサイトの画像やHTML、接続情報などを取ることが出来る。
タグを指定できれば、ピンポイントでデータが取れるということですね。
