
前回は、対話形式のREPLを使ってDOM要素を取り出してみました。
今後、どうやって使っていくか分かっていませんが。

今回は、urlopenとBeautifulSoupを使って郵便番号から住所を取得します。
参考にしている本

BeautifulSoupのおさらい
BeautifulSoupは、HTMLやXMLを解析するライブラリでした。

前回は、ソースの中にHTMLを書いて、そのソースの中から要素を抽出する例を勉強しました。
今回は、ソースの中にURLを書いて解析する仕組みですので、実用性がありそうです。
#ライブラリを取り込む
from bs4 import BeautifulSoup
import urllib.request as req
url = "https://***************/zip/xml/1500042"
#urlopen()でデータ取得
res = req.urlopen(url)
#BeautifulSoupで解析
soup = BeautifulSoup(res,"html.parser")
#データを抽出
ken = soup.find("ken").string
shi = soup.find("shi").string
cho = soup.find("cho").string
print(ken,shi,cho)
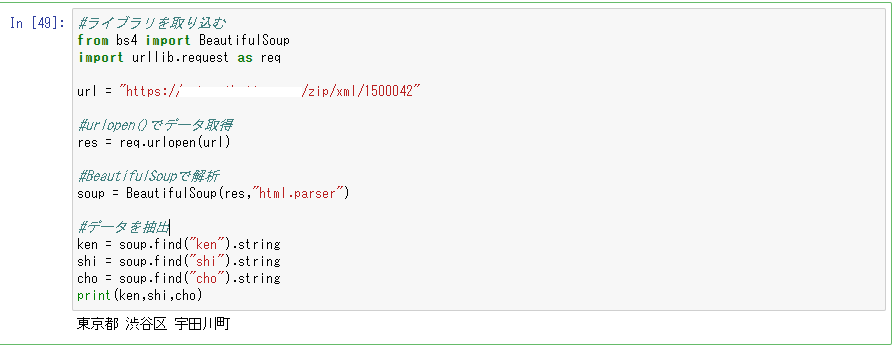
urlにURLを入れておけば、urlopenで開いて、BeautifulSoupで解析して、データを抽出することが出来ました。
urllib.requestの中のurlopenってことですね。
urllib.request.urlopen
urllib.request は URL を開いて読むためのモジュールです。
urllib.requestの中にurlopenをいう関数があります。
インポートにはfromとimport がある
BeautifulSoupをインポートするときはfrom
urllibをインポートするときはimport
なぜ?
fromは「bs4」=「Beautiful Soup 4」というライブラリの中にある 「BeautifulSoup」という関数だけをインポートします。
BeautifulSoupだけしかインポートしていないので、解析するときに BeautifulSoup()だけで使えるということになります。
「soup = BeautifulSoup(res,”html.parser”)」
importを使った場合
fromでは、ライブラリの中の関数だけをインポートできますが、importでは、ライブラリ全体を読み込む感じですかね。
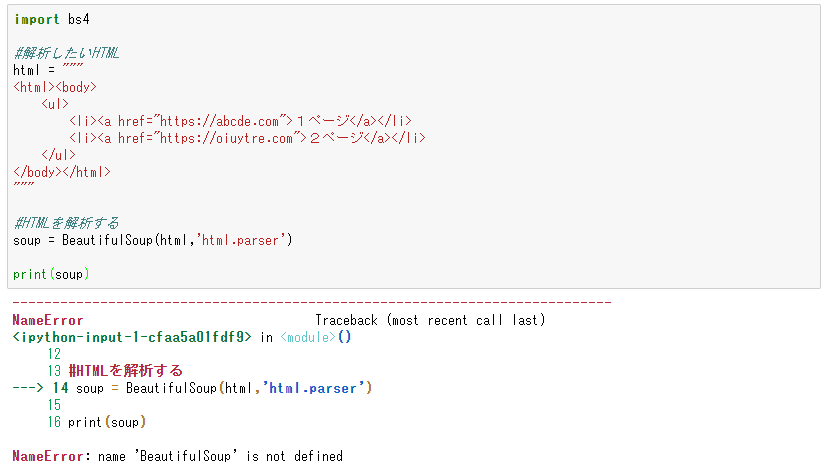
importしか使わないとエラーになります。BeautifulSoupが見つからないですね。
importの場合は、全体がインポートされるので、実行時は「どこの」を指定してあげないといけないことが分かりました。
soup = bs4.BeautifulSoup(res,”html.parser”)

formとimportの違い
- from bs4 import BeautifulSoup
- import bs4
1はbs4ライブラリの中のBeautifulSoupだけをインポートできるので、実行時はライブラリ名を省略できる。
2はbs4全体がインポートできるので、実行時にライブラリを指定する。
なので、
BeautifulSoupしか使わないよ、というときはfromでOKで、コードが簡潔に書けるので便利。何度もライブラリを指定しなくて良いですからね。
BeautifulSoup以外も使うよ、という場合はimportですね。
言葉で混乱してきた
本の中では、「ライブラリ」をインポートすると記載がある。
ネット上のサイトでは「ライブラリ」というサイトと「モジュール」というサイトがある。
関数であったりクラスだったり、ちょっとワケが分からなくなってきました。
