
先週はPIPが分からなくて困りました。

なんとかインストールできたので、気を取り直してやっていきましょう。
参考にしている本

BeautifulSoupを使う
BeautifulSoupはスクレイピングのライブラリです。
前節で使ったurllibでもファイルをダウンロードしたり、サイトのデータ持ってくることが出来ましたが、BeautifulSoupはHTMLやXMLを解析するのがメインみたいですね。
BeautifulSoupで解析してurllibでダウンロードするのかな?
#ライブラリを取り込み
from bs4 import BeautifulSoup
#解析したいHTML
html = """
<html<body>
<h1>スクレイピングとは?</h1>
<p>webページを解析すること</p>
<p>任意の箇所を抽出すること</p>
</body></html>
"""
#HTMLを解析する
soup = BeautifulSoup(html,'html.parser')
#任意の場所を抽出する
h1 = soup.html.body.h1
p1 = soup.html.body.p
p2 = p1.next_sibling.next_sibling
#要素のテキストを表示する
print("H1 = " + h1.string)
print("p = " + p1.string)
print("p = " + p2.string)
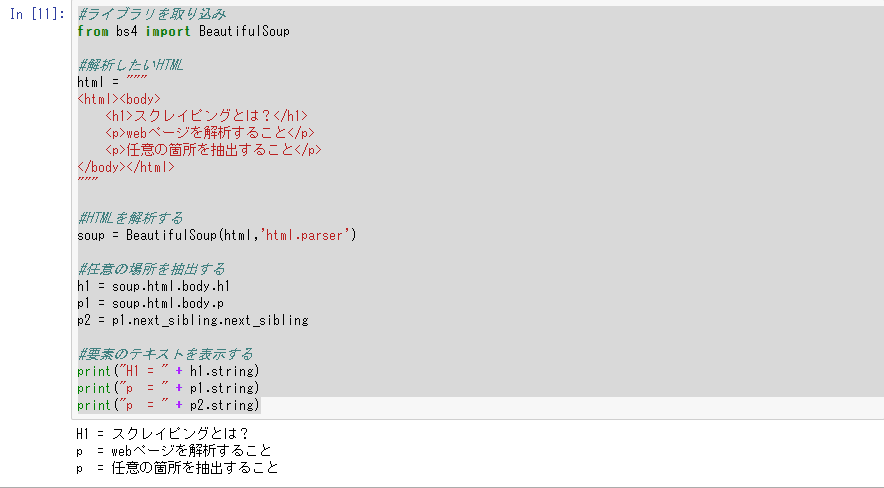
結果が表示されました。
実は1回エラーになっています。それは
「BeautifulSoup」を小文字「 beautifulsoup 」と書いたことでエラーになった。大文字小文字判断しているんですね。

課題と解説
「#解析したいHTML」 ”””が3つ付くのは「”」を「””」で挟んでいるから3つになるのかな?
「#HTMLを解析する」では」BeautifulSoupのインスタンスを「soup」として作成します。(カッコ)の中のhtmlは引数で、htmlが入ってます。
次の引数に、parser(パーサー)の種類みたいです。よくわからないのでこういうものだということで覚えておきます。
「#任意の場所を抽出する」は、ここまでやってくると何となくわかりますね。soupインスタンスのhtmlのbodyのh1をh1に入れろ。的な。
p2はnext_siblingが2回繰り返されています。
htmlの中には<p>が2回あると思いますが、次の<p>を取ってくるみたいですね。
p1 = soup.html.body.p 一個目はP1に入れなさい
p2 = p1.next_sibling.next_sibling 次の次を入れなさい。
ん?次じゃなくて、次の次?
動作確認
html = """
<html<body>
<h1>スクレイピングとは?</h1>
<p>webページを解析すること</p>
<p>2つ目P</p>
<p>3つ目P</p>
</body></html>
"""
これだと空欄になります。

html = """
<html<body>
<h1>スクレイピングとは?</h1>
<p>webページを解析すること</p><p>2つ目P</p>
<p>3つ目P</p>
</body></html>
"""
これだと、「2つ目P」が表示されます。

つまり、わからん。
私の頭は単純で助かる。
<p>webページを解析すること</p>
<p>2つ目P</p>
<p>3つ目P</p>
・・・・
#任意の場所を抽出する
h1 = soup.html.body.h1
p1 = soup.html.body.p
p2 = p1.next_sibling
p3 = p1.next_sibling.next_sibling
p4 = p1.next_sibling.next_sibling.next_sibling
p5 = p1.next_sibling.next_sibling.next_sibling.next_sibling
#要素のテキストを表示する
print("H1 = " + h1.string)
print("p1 = " + p1.string)
print("p2 = " + p2.string)
print("p3 = " + p3.string)
print("p4 = " + p4.string)
print("p5 = " + p5.string)

p1 = soup.html.body.p → 1つ目のP p2 = p1.next_sibling → 空欄じゃなくて改行だな p3 = p1.next_sibling.next_sibling → 2つ目のP p4 = p1.next_sibling.next_sibling.next_sibling → 改行 p5 = p1.next_sibling.next_sibling.next_sibling.next_sibling → 3つ目のP
つまりこういうことですね。
next_siblingは次の要素みたいなものを意味してる。
やってることはわかったけど、1ページをこれで解析してデータを持ってくるのは相当面倒だと思いました。
そのうち簡単に場所を特定できることを期待して、今日はこの辺で。
