
REPLは、pythonの対話形式実行環境。
DOMはDocument Object Modelです。階層構造にアクセスするみたいな。
スクレイピングなのでWEBからデータを持ってくる際に、タグの構造がが分かるとデータにアクセスしやすいですよね。そういうことです。
説明難しいので、やってみます。

参考にしている本

REPLを起動
コマンドラインで「python3」と入力します。
は?(笑)
python3と打ったらMicrosoft Storeが立ち上がった。
はは~ん、またあれだ。パスが違うパターンだな。
「python.exe」を立ち上げれば良いことに気づくと解決します。
私の場合は、Anaconda3の中にあって、しかもpython3ではなくpython.exeでした。Anaconda環境だと違うみたいですね。
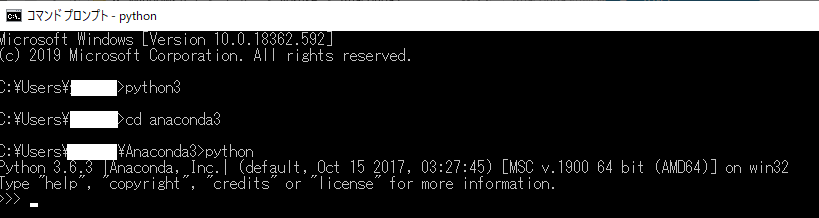
この画面の>>>のところにコードを書いていくと、結果が返ってきます。
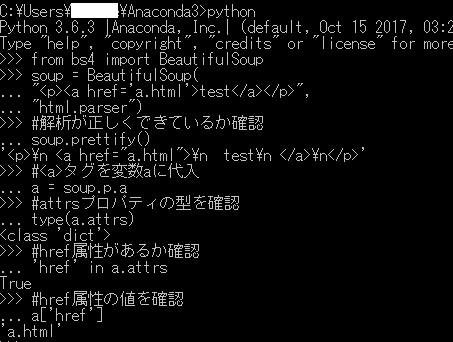
本とちょっと違うところは、本「>>>」のところが実際「…」となってますが、動いているから良いのかな。
BeautifulSoupをインポートして、SoupにHTMLを代入します。
soup.prettifyメソッドをすると解析できているか確認できます。
a = soup.p.a はsoupの<P>の<a>ってこと?
で、aに対してtypeでattrsプロパティの型を確認。
結果、dict型であることはわかりますし、hrefもあることが分かります。
とりあえず確認はできたが、何か意味があるのかわからない
‘a.html’は”(ラブルクォーテーション)の中なので’シングルクォーテーションを使ってる?
attrsプロパティの型は確認できたし、hrefがあるかの確認方法のコーナーだとしたら、理解。
実際に実装するときは、REPLで確認しなさいよ。その時の方法はこれが良いよってことなんですかね。
