
前回「next_sibling」で次の要素が取れるのが分かって、順番に追っていくのは面倒だって書きましたが、なんと次のページに任意の要素が取れる方法がありました。
「任意のidで要素を探す方法」このタイトルでピンとこない。
予習せず、ガチで読みながら書いているPython学習です。

参考にしている本

任意のidで要素を探す方法
id がなんだかわからずピンときませんでしたが、htmlのタグについているやつですね。本を読んで理解しました。
#ライブラリを取り込み
from bs4 import BeautifulSoup
#解析したいHTML
html = """
<html><body>
<h1 id="title">スクレイピングとは?</h1>
<p id="body">webページから任意のデータを抽出</p>
</body></html>
"""
#HTMLを解析する
soup = BeautifulSoup(html,'html.parser')
#find(メソッド)で取り出す
title = soup.find(id="title")
body = soup.find(id="body")
#テキスト部分を表示
print("#title = " + title.string)
print("#body = " + body.string)

「title = soup.find(id=”title”)」
これが新しいところで、それ以外は前回とほぼ一緒ですね。
soup.findでidがtitleの物を探して、title変数に入れるという命令ですね。
特に疑問点はないですね。
コマンドラインから実行
本の中では、コマンドラインから実行してみましょう、となってます。
4日目でわからず苦戦したやつですね。

はい。え~どうだったか。
苦労した割には、パッと出てこない。
python.exeが「C:\Users\(user)\Anaconda3」にあるので、同じところに「bs-test2.py」でテキストに書いて、拡張子をpyにして保存。
コマンドプロンプトで、bs-test2.pyを実行する。
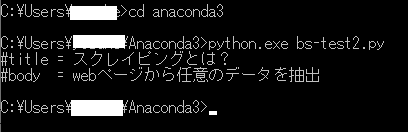
#title と #body が取れていますね。
この頭についている「#」は何でしょうね。無くても動きます。


うん、使い方は大丈夫。
複数の要素を所得する
ページの中の1つの要素を持ってくることはわかりましたが、次はページの中のいくつかの要素を持ってくる方法です。
埋め込まれているリンクとか。
ソースは上の使いまわしです。
#ライブラリを取り込み
from bs4 import BeautifulSoup
#解析したいHTML
html = """
<html><body>
<ul>
<li><a href="https://abcde.com">1ページ</a></li>
<li><a href="https://oiuytre.com">2ページ</a></li>
</ul>
</body></html>
"""
#HTMLを解析する
soup = BeautifulSoup(html,'html.parser')
find_all(メソッド)で取り出す
links = soup.find_all(id="a")
#テキスト部分を繰り返し表示
for a in links:
href = a.attrs['href']
text = a.string
print(text,">",href)
結果が出ない。
どこがおかしいか確認する方法を発見
Print()を使うと、どこまで変数が入っているか確認することに気が付きました。
VBAとかは見ることが出来るのですが、pythonって見る方法あるのかな?
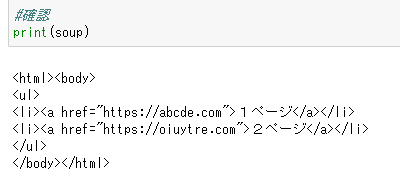
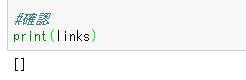
これだ!
#find_all(メソッド)で取り出す
links = soup.find_all(id=”a”)
正解は「 links = soup.find_all(“a”) 」でした。
前の使いまわしていたのでそのまま使ってました。
繰り返すからidは指定しない。
デバックの方法はあるのかも知れないけど、今の段階では「Print()」便利。

「for a in 」の使い方はまだ記載はないけど、繰り返すことはわかった。
他の言語でもありますしね。
href = a.attrs[‘href’]
「attrs 」はプロパティでリンク属性?
調べてきます。
エラーは出るけど、ちょっとおもしろくなってきた。
