
昨日はコマンドラインからの実行で苦戦したけど、なんとか動いて良かった。
こうやってブログにまとめていかないと、どうやって解決したか忘れてしまいそうなので、続けていきましょう。

1-1まとめ
4日で1節が終了しました。少し遅いな~という感じ。
この本は7章まであるから、まだまだ先が長い。
気長に時間を見つけて取り組んでいきます。
参考にしている本

1-2 BeautifulSoupを使う
BeautifulSoupはスクレイピングのライブラリです。
前節で使ったurllibでもファイルをダウンロードしたり、サイトのデータ持ってくることが出来ましたが、BeautifulSoupはHTMLやXMLを解析するのがメインみたいですね。
BeautifulSoupで解析してurllibでダウンロードするのかな?
BeautifulSoupのインストール
BeautifulSoupを使うにはインストールが必要です。
ですが、Pythonのインストールは、パッケージの中に入っているので、コマンド1つでインストールができるので、簡単で良いですね。
インストールするには、次のコマンドが必要です。
$ pip3 install beautifulsoup4
え?どこで?jupyterで?
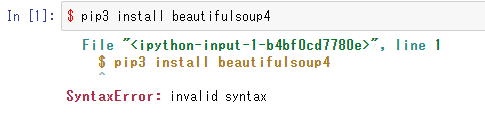
でしょうね~
はは~ん、コマンドプロンプトだな。

コマンドプロンプトには、WindowsのものとAnacondaの物がありました。
気を取り直して、
じゃん!

一緒じゃん。
試行錯誤の結果
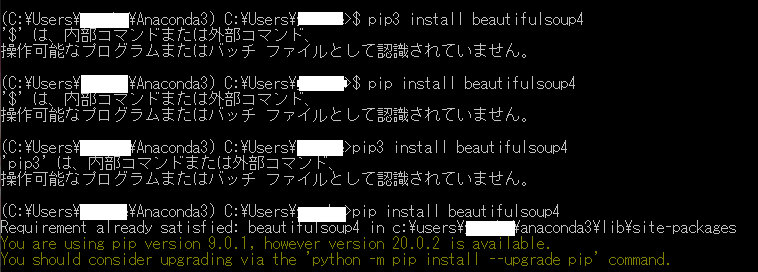
結論としては、「$」は要りませんね。
あとpip3では動かずpipにしたら行けたみたいです。
入りましたよって表示されているので、フォルダを見に行ったらありました。

慣れてしまえはなんてことないのだろうけど、「1から始める~」という方はPythonって環境の構築のほうで苦労するかも知れないですね。
今回はこの辺で。
