
BeautifulSoupで、青空文庫で公開されている「江戸川乱歩」の作品一覧を取得してみます。
技術的には、前回やったYahoo為替情報を取るのと同じような内容です。

参考にしている本

青空文庫
青空文庫は、著作権が消滅しているような公開できる書籍を電子データとして公開してくれているサイトです。
青空文庫のデータをお借りしてBeautifulSoupを試します。
ソースコード
#ライブラリを取り込む
from bs4 import BeautifulSoup
import urllib.request as req
#データ取得
url="https://www.aozora.gr.jp/index_pages/person1779.html"
res = req.urlopen(url)
#BeautifulSoupで解析
soup = BeautifulSoup(res,"html.parser")
#リストの部分を繰り返し取得
li_list = soup.select("ol > li")
for li in li_list:
a = li.a
if a != None:
name = a.string
href = a.attrs["href"]
print(name,">",href)
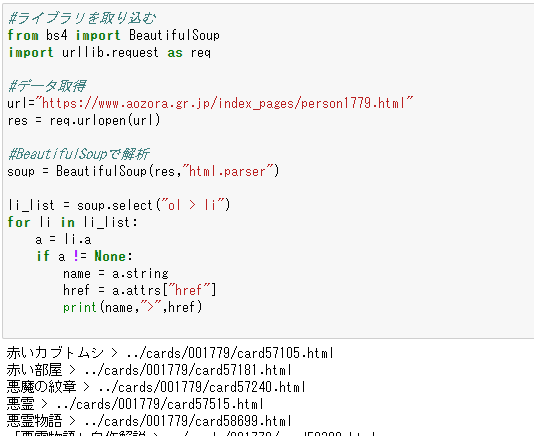
コード解説
半分目までは、前回を同じなので省きますが、URLに関して少し補足します。
サイト上から「江戸川乱歩」に遷移した場合のURLは

でした。
後ろのほうの、「#sakuhin_list_1」というのは、ページの中のアドレスみたいなものなので、あってもなくても問題はありませんでした。
ここでは省略しました。
では、下半分の説明です。
li_list = soup.select(“ol > li”)
li_list という変数にoiタグの中のliタグが入ります。
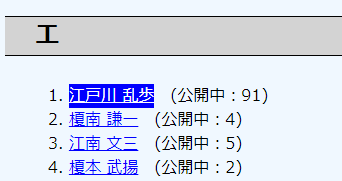
ページを開発者ツールで確認すると、下図のようになっています。
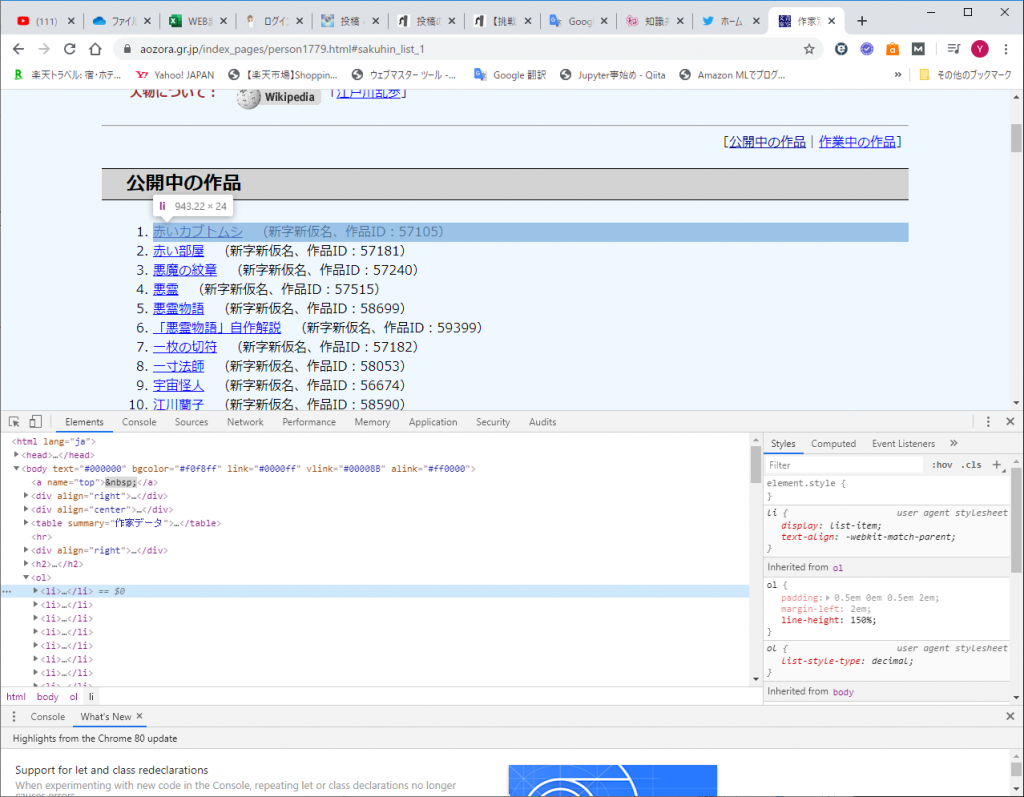
<li>…</li>の中に情報が入っています。
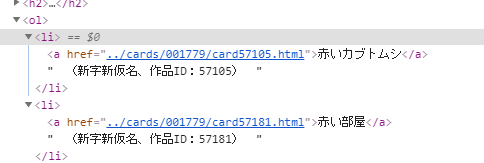
このリンクとタイトル、作品IDという情報をli_list入れていってます。
for li in li_list:
これは繰り返しで、li_listに上で入った情報をliという変数に1つずつ取り出しています。
この時点で、「li_list」には
[<li><a href=”../cards/001779/card57105.html”>赤いカブトムシ</a> (新字新仮名、作品ID:57105) </li>, <li><a href=”../cards/001779/card57181.html”>赤い部屋</a> (新字新仮名、作品ID:57181) </li>…という状態で入ってました。
<li><a></a></li>の繰り返しです。
1回目= <li><a href=”../cards/001779/card57105.html”>赤いカブトムシ</a> (新字新仮名、作品ID:57105) </li>
2回目= <li><a href=”../cards/001779/card57181.html”>赤い部屋</a> (新字新仮名、作品ID:57181) </li>
おそらくこんな官位にli_listに入っていくのだと思います。
a = li.a
これが最初よくわかりませんでしたが、たぶん次の感じです。
forで1つずつ「li」に情報は入ってますが、<li>の<a>タグを取り出して、ということかな。
なので、変数aにliの中のaを入れてることになってると思います。
1回目a=<a href=”../cards/001779/card57105.html”>赤いカブトムシ</a>
2回目a=<a href=”../cards/001779/card57181.html”>赤い部屋</a>
これ、変数のaとHTMLタグのaがあるので、すごく混乱します。
printで確認しようと思いましたができませんでした。でもたぶんこんな感じで動いています。
ちょっと初心者には優しくない書き方ですね。
if a != None:
「!=」は比較演算子で、「a」と「None」が等しくない場合の処理です。
この本には、構文の基本的な情報は掲載されていないので、詳しく知りたい方は別の書籍もセットで購入したほうが良いです。
name = a.string
テキストは、stringプロパティでとって変数nameに入れる。
href = a.attrs[“href”]
このattrsは前にわからなかった部分ですが、herf属性は、attrsプロパティでattrs[herf]とすると取れる。そして、変数hrefに入れる。

print(name,”>”,href)
毎度おなじみの出力。
まとめ
内容的には、何をやっているかは理解することが出来ました。
若干、繰り返しの部分で変数に代入しているところが分かりにくいので、理解に時間はかかりますが、なんとか。
スクレイピングを行うにはHTMLやCSSも理解しておくべきですね。
多少知識はあるので見ることはできますが、まったく0からだと結構苦戦するかも知れません。
